阶段式同步(staged sync)重构自 Go-Ethereum 的完全同步模式(full sync),以实现更好的性能。
阶段式同步需要进行大量读写操作。虽然我们的目标是能够在机械硬盘上同步节点,但是我们仍建议使用固态硬盘。
顾名思义,阶段式同步需要依次执行 10 个阶段。
阶段式同步是如何运作的
Turbo-Geth 客户端会向每个对等节点了解该节点的 HEAD 区块(即最新区块),然后依次执行每个阶段、寻找本地 HEAD 区块和对等节点的 HEAD 区块之间缺失的区块。
第一个阶段(下载区块头)会设置本地 HEAD 区块。
各阶段会按顺序执行。在每个阶段执行期间,只有节点本地的状态达到目标状态,该阶段才会结束。
也就是说,在理想情况下(没有出现网络中断、应用没有重启等问题),每个阶段只需执行一次,即可完成初始同步。
最后一阶段结束后,整个同步流程会重新开始,寻找新的区块头下载。
如果你在两个阶段之间重启应用,应用会从第一阶段开始重启。
如果你在某个阶段执行期间重启应用,应用会从当前阶段开始重启,以完成该阶段。
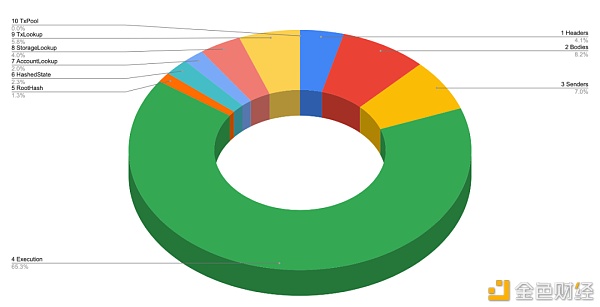
每个阶段需要耗时多久?
通过下方的饼状图,我们可以看出每个阶段的耗时占比(这些都是从完全同步中得出的数据)。虽然这些数据并不精确,但是足以作为参考。
重组/回退
如果区块链发生重组,我们需要“回退”部分同步数据。
回退指的是从最后一个阶段倒退回第一个阶段。但是,需要注意的一点是,我们执行完回退之后才会更新交易池,因此我们知道新的 nonce 。
回退的阶段顺序如下例所示(从右往左依次发生)。
state.unwindOrder = []*Stage{
// Unwinding of tx pool (reinjecting transactions into the pool needs to happen after unwinding execution)
stages[0], stages[1], stages[2], stages[9], stages[3], stages[4], stages[5], stages[6], stages[7], stages[8],
}
通过?ETL?进行预处理
在将数据插入数据库之前,一些阶段会使用我们的 ETL 框架根据键值对数据进行排序。
这样就可以极大减少数据库写入放大(write amplification)的情况。
因此,当我们生成索引或者说哈希值化状态(Hashed State)时,我们会执行一个多步骤流程。
将处理过的数据写入位于数据目录的几个临时文件中;
然后使用一个堆栈(heap)把临时文件中的数据插入到数据库中,并且使按照能够最小化数据库写入放大现象的顺序插入数据。
这种优化有时会将写入速度提高几个数量级。
各阶段(如需查看最新列表,请访问stagedsync.go)
每个阶段都包含两个函数,分别是向前推进阶段的ExecFunc?和向后回退阶段的?UnwindFunc。
从理论上来说,部分阶段可以离线工作,但是当前版本并未实现这一功能。
阶段 1 :下载区块头
在这一阶段,我们会下载本地 HEAD 区块和对等节点的 HEAD 区块之间的所有区块头。
这一阶段是 CPU 密集型的,适合使用多核处理器,因为要验证区块头的工作量证明。
由于区块链重组,大多数回退都是在这一阶段开始的。
这一阶段会推动本地 HEAD 的指针(指向更新的区块)。
阶段 2 :区块哈希值
从区块头中抽取出一个从区块哈希值映射成区块号(blockHash -> blockNumber)的索引表,以支持更快速的查找功能,并让同步过程对机械硬盘更为友好。
阶段 3 :下载区块体
在这一阶段,我们会将上一阶段已下载区块头的区块体也下载下来。
这一阶段需要保持良好的联网连接。绝大多数数据都在这一阶段下载。
阶段 4 :复原发送者
这一阶段会复原出并存储每个已下载区块中的每笔交易的发送者。
这一阶段同样是 CPU 密集型的,适合使用多核处理器。
这一阶段不需要联网。
阶段 5 :执行区块
在这一阶段,我们会执行之前下载的所有区块中的每一笔交易。
需要注意的一点是,在执行区块的过程中,我们不会验证根哈希,甚至不会创建默克尔树。
这一阶段是单线程的,无需联网,需占用大量磁盘空间。如果区块执行失败,可以回退该阶段。
阶段 6 :计算状态根
这一阶段会构建默克尔树,并验证当前状态的根哈希。
这一阶段也会构建中间哈希值(Intermediate Hashes),并将它们存储到数据库中。
如果之前没有存储任何中间哈希值(这种情况可能在第一个初始同步期间发生),这一阶段会构建出完整的默克尔树及其根哈希。
如果数据库中没有中间哈希值,这一阶段就会利用区块的历史记录来弄清楚哪些哈希值已经过时,哪些哈希值是最新的,然后使用最新的哈希值来构建部分默克尔树,只重构过时的哈希值。
如果根哈希无法匹配,就会向后回退一个区块。
这一阶段不需要联网。
阶段 7 :生成哈希值化状态
在执行期间,Turbo-Geth 使用无格式状态存储(Plain state storage)。
无格式状态(Plain State):在标准状态(我们称之为 “哈希值化状态”)中,账户和存储项的地址是?keccak256(address)?,但是在一般状态中,二者的地址就是?address?。
尽管如此,为了确保一些 API 能够正常运作并与其它客户端保持兼容,我们也会生成哈希值化状态。
如果哈希值化状态不是空值,我们会查看历史记录变更集(History ChangeSet),并且只更新已更改的项。
这个阶段不需要联网。
阶段 8、9、10?:生成索引
同步期间会生成 3 个索引。
这 3 个索引可能会被禁用,因为所有 API 都不使用它们。
这一阶段不需要联网。
交易查询索引
该索引表由从交易哈希值到区块号的映射构成。
账户历史索引
该索引存储了从账户地址到区块列表(在这些区块中,该账户的状态有了更改)的映射。
存储历史索引
该索引存储了从存储项地址到区块列表(其中,该存储项在一定程度上有了更改)的映射。
阶段 11 :交易池
在这一阶段,我们会启动交易池或更新其状态。例如,如果我们已下载的区块中包含了某些交易,就把这些交易从交易池中移除。
在回退时,我们会将被回退的区块中的交易重新添加到交易池中。
这个阶段不需要联网。
原文链接:
https://github.com/ledgerwatch/turbo-geth/tree/master/eth/stagedsync
作者:?Alex Sharov
翻译&校对: 闵敏?&?阿剑